Building an Agentic Design to Code Workflow
Creating an AI workflow that reads Figma designs, maps every value to our design tokens, reuses existing components, and produces pixel-perfect code from a single command.
Claude Code, Figma MCP, DTCG Tokens, Style Dictionary
The catalyst
When our company started adopting AI tools in our workflow, agentic coding tools looked like a real opportunity for the design and front end teams. The idea was that designers could build and design in code at the same time, getting full confidence in the result before handing anything off, and developers could spend their time on logic, data, and tracking instead of fixing padding and layout issues. Design debt had been piling up on our team for a while. Things like inconsistent spacing, off-by-a-few-pixels components, alignment problems that never made it into a sprint because there was always something more urgent. This was a natural place to start.
Make the machine do what humans forget
I started experimenting with Claude Code and Figma's MCP integration. The idea was simple: if Claude can read Figma designs and I can teach it our token system, it should be able to produce code that matches Figma exactly without anyone manually translating values. What started as a prompt engineering exercise became a full agent workflow over several weeks of iterating, breaking things, and rebuilding.
Layer 1: The token pipeline
Our design tokens are split across three files in DTCG format: primitives.json has raw values like color scales and spacing units, tokens.json has semantic tokens that reference primitives (like "color.action.primary" pointing to a blue in the scale), and typography.json has font families, sizes, weights, and line heights that also reference primitives. The rule is that components only ever touch semantic tokens, never primitives directly. I wrote a generator script that resolves all the aliases across the three files and outputs shared CSS variables and a TypeScript constants file that the whole monorepo imports from one place.

Layer 2: The component registry
Early on, I made a mistake that taught me something important. My first version auto-generated a full component library from the tokens: buttons, cards, inputs, all scaffolded from the palette. They looked right in isolation but didn't match Figma at all because they were invented, not built from actual designs. So I scrapped that and started over with the opposite approach: the library starts empty. Components only get built when they appear in a Figma design, and they're built to exact Figma spec. Every component gets registered in a shared markdown file with its props, variants, source Figma link, and a "Does NOT cover" line that explicitly states what Figma didn't define. That line is what stops the agent from silently adding a loading state or a ghost variant that was never designed.
Figma calls it "Buttons/Primary." Code calls it Button. If the names don't match, the agent builds a duplicate and nobody notices.
Solving the naming mismatch
When the agent reads a Figma screen, it gets back layer names and component names exactly as Figma stores them. If Figma calls something "Buttons/Primary/Default" and the registry has "Button," the agent has to infer the match. Sometimes it got it right. Sometimes it quietly rebuilt the whole thing. The fix was adding a Figma name field to every registry entry that maps Figma's naming to the code naming. No inference, no guessing. During the pre-build audit, exact matches show as confirmed reuse, partial matches get flagged for confirmation, and anything unrecognized gets listed as new.

Layer 3: Typography as a type library
Typography was the messiest part. Our typography.json had individual primitives (font families, sizes, weights) but no composite styles combining them. And our Figma Text Style names were completely different from the token paths. I went through a few iterations: a separate mapping file, a separate generator step, a sync command. Too many moving parts. I simplified it to one step: during bootstrap, the agent reads Figma Text Styles via MCP, matches each property value against our resolved token values, and writes a single textStyles.ts file. Components import from it and spread one object per text element. No individual font-size or font-weight references anywhere in component code.

Vesper: the agent
All of this came together into an agent I named Vesper. It's a design engineer: part pixel freak who notices if a border radius is off by 2px, part product designer who flags missing hover states and contrast failures, part frontend engineer who keeps the codebase clean.I also gave it taste by feeding it the best design principles and case studies on the internet.
Keeping the agent fast
The workflow documentation grew to nearly 700 lines in a single file. The agent was reading bootstrapping instructions on every build even though bootstrap only runs once. I restructured into three files with progressive disclosure: vesper.md (role, taste and routing), figma-workflow.md (the build phases, loaded per request), and figma-bootstrap.md (first-time setup, loaded once). I also split out a code-workflow.md for building screens without Figma using only existing tokens and components. That workflow is more constrained: if a component doesn't exist, it gets built as a one-off inline until you review and explicitly promote it.
"Build this screen: [Figma link]." That's the entire interface. Vesper handles the rest.
What happens under the hood
Vesper reads the Figma link via MCP. It pulls out every layer, every auto layout frame, every color and spacing value. It maps each value against our tokens and flags anything missing. It checks the component registry for existing components, matching by Figma name. It shows you a full audit before writing any code: what it's reusing, what needs to be built new, and what's missing. You confirm, and it builds. Every auto layout frame becomes a flex div. Every color, spacing, and radius value references a token. Every text element uses the type library. New components get registered immediately. If it runs into something unexpected, it stops and asks.
Packaging for the team
I packaged Vesper as a remote-installable agent for Claude Code. The repo lives on GitHub, and anyone on the team installs with a single curl command. It copies the agent definition into .claude/agents/ (so you can summon it with @vesper) and the workflow files, design principles, and token generator into a .vesper/ folder. The same command handles updates. Token JSON files and the shared output folder stay in the user's project since those are project data, not agent instructions.

What I took away from this
The biggest lesson was about where to put the rules. I kept trying to make the AI smarter about inferring things: matching component names, guessing typography tokens, knowing when to reuse. Every time, the answer was the same. Don't make it smarter, make the data more explicit. An exact Figma name field in the registry beats fuzzy matching. A "Does NOT cover" line beats trusting the agent not to over-build. A routing file that runs before MCP beats a clever skill description. The whole system works because the constraints are precise, not because the AI is clever.
When the agent met the real monorepo
The first time I ran Vesper inside our actual sidelineHD monorepo, the result was catastrophic. Components looked nothing like the designs. The agent kept rebuilding things that already existed in the codebase. It took me a while to figure out what was going wrong. Claude Code was calling the Figma MCP tool before it ever read my workflow. The whole point of the workflow was to read tokens and the component registry first, then fetch Figma context, so the agent could match values against what was already there. Instead, it was grabbing Figma data cold and inventing everything from scratch. Vesper supposed to be the gate, but it didn't have enough override power against a built-in tool that was already wired up. On top of that, our monorepo was full of legacy markdown files. Old Grommet conventions, deprecated component docs, style guides from years ago. The agent was reading all of them, and some of them directly contradicted what I'd written in the workflow.
A clean room: shd-design-library
Instead of fighting the monorepo, I built a separate library repository from scratch. It would be published as an npm package and consumed by the main app. The new repo had nothing in it that could compete with the workflow. Storybook was wired in from day one so I could preview every component in isolation before any of it touched production code. The library would live as a standalone npm package, expose CSS custom properties for tokens, and stay in sync with Figma at every step.
Killing the agent persona
Within a day of creating a separate repo, I made a decision that contradicted my earlier work. I deleted the named agent. Vesper as a persona was creating indirection. The agent wrapper had its own context it needed to load before it could even read the workflow, which meant more places for things to go sideways. I moved everything to direct CLAUDE.md routing with progressive disclosure. The workflows survived but the persona didn't. CLAUDE.md now points directly to the right workflow file based on the task. "Build from Figma" routes to one workflow, "build without Figma" to another, "publish" to a third. The result? 75 components built to pixel perfection with no hard-coded value. It even got the baseball field diagram right, which was the toughest one to build.
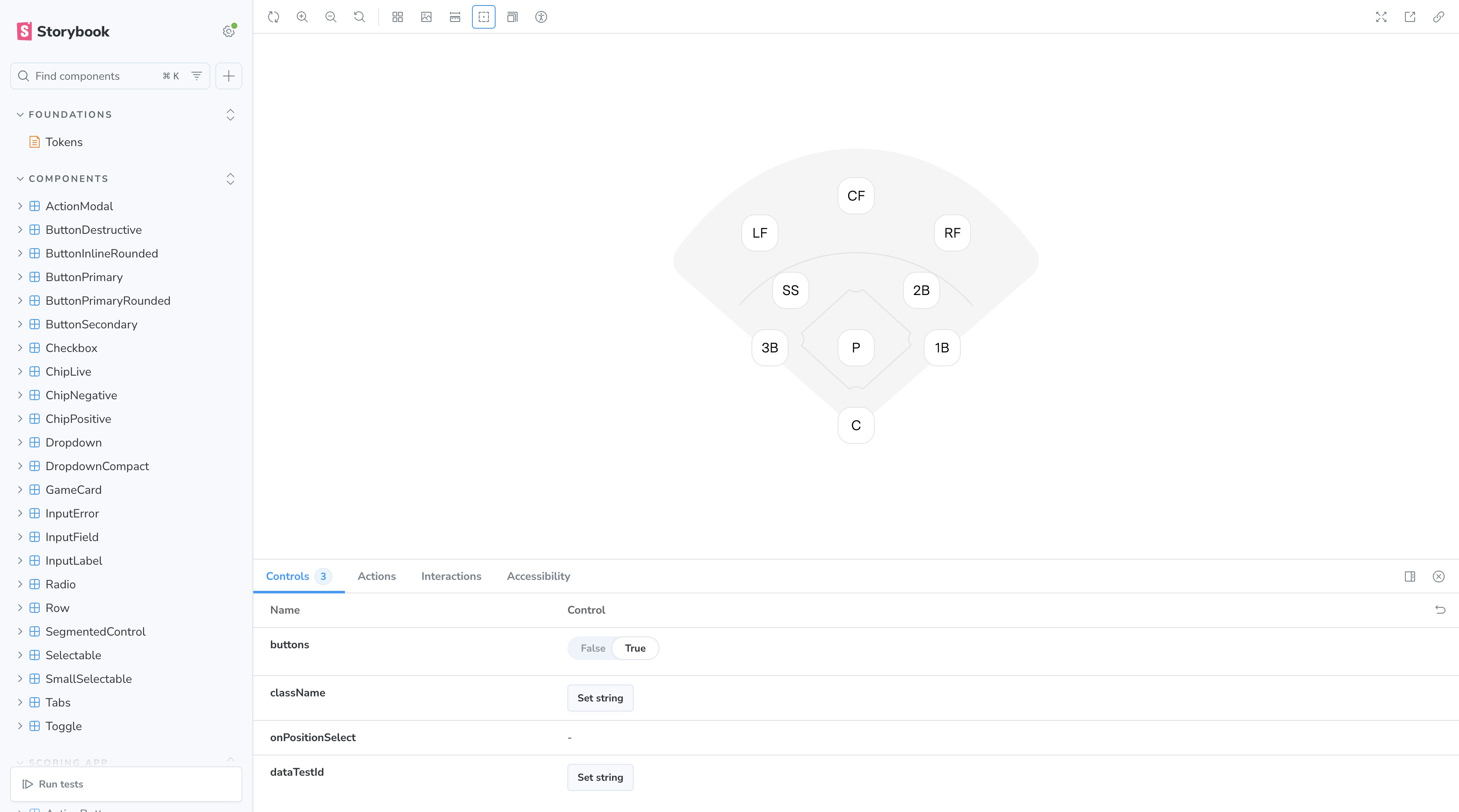
Why the second attempt worked
The biggest difference between the failed monorepo run and the clean library build wasn't technical. It was environmental. A clean repo has no competing instructions. Every markdown file the agent reads is one I wrote, and every one of them points in the same direction. CLAUDE.md no longer had to fight against legacy docs or Figma MCP routing because there was nothing else to compete with. The component registry stayed honest because nothing was bypassing it. Storybook caught visual regressions before they could spread. And the npm package boundary kept the library and the consuming app from cross-contaminating.




